
先讲仿射变换和双线性插值怎么做
就是把原本的坐标矩阵做一个线性变换,得到新的坐标矩阵,然后由于这个坐标矩阵里面有的不是整数,因此做双线性插值,对output的矩阵上每一个像素P(x,y)来说,它去变换出来的那小数矩阵上,根据公式计算它应该有的像素。

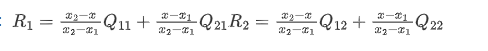
然后再看STN
由此可见三个部分:
- Localisation net :参数预测
- Gridgenerator :坐标映射
- ***Sampler:***像素采集
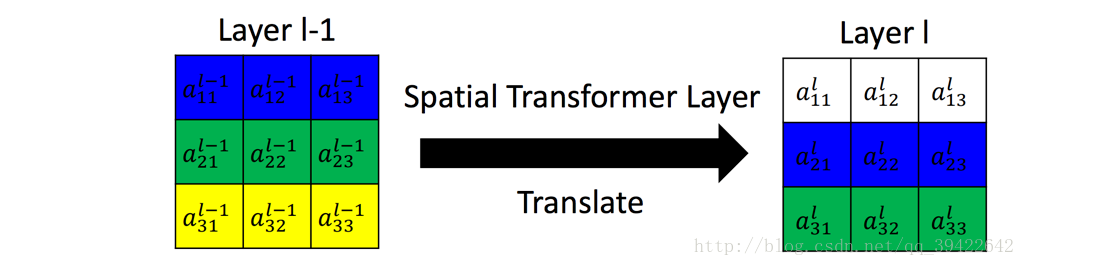
听起来和玄乎,第一个参数预测其实就是前面说的仿射变换,对于图片来说,一个(2,3)的矩阵就可以完成各种变换(旋转,平移,放大,缩小)
第二个坐标映射就是 拿原本的坐标矩阵乘上仿射变换的矩阵,得到一个新的坐标矩阵 $X^S$
由于新的坐标矩阵可能有小数,要做处理,这里有两种方式,一种是向前映射,就是将新坐标对应的点(浮点数坐标的点)根据其周围四个点的位置,把自己的值按照权重分给周围四个点,最后结果是原本映射的像素点按照一定权重叠加出来的矩阵。
还有一个是向后映射,就是说我们最终output出来的这个新矩阵,它的shape我们是知道了,那根据它的每个点坐标,根据逆映射,可以找到对应原图像上的一个坐标(但是可能存在浮点数),然后用这个浮点数坐标周围的四个点来进行插值,就能计算出一个个的像素。(我本来以为这个地方要对变换矩阵求逆,但是其实不用,在初始定义的时候,变换矩阵就没有卡死说是对谁的变换,而且参数也是随着梯度下降逐渐更新的,所以一开始做坐标映射的时候就向后映就ok了)
反向传播我没有推,但是据说这样的方法是可以正确回传的,放上公式把。

还有Pytorch官方的tutorial Spatial Transformer Networks Tutorial — PyTorch Tutorials 1.9.0+cu102 documentation
然后我在李宏毅2021的HW3里试了一下这个,但是由于HW3里本身就做过Data-aug,所以效果可能不是太好,而且具体超参数我也懒得调。
官方给的代码里面还是有很多东西的
1 | class Net(nn.Module): |